
DAY 2
Computer Architecture
고정 소수점 / 부동 소수점 = 컴퓨터에서 실수를 표현하는 두 가지 주요 방법
1. 고정소수점(Fixed-point) = 정수 + 소수
- 숫자를 표현하는 방법 중 하나로, 소수점의 위치가 고정되어 있다. 이는 정수부와 소수부의 길이가 항상 일정하다는 것을 의미한다. 이 방식의 장점은 구현이 간단하고 연산 속도가 빠르다는 것이다. 하지만 표현할 수 있는 범위가 제한적이다. 따라서 고정소수점은 주로 간단한 연산이 필요하거나, 연산 속도가 중요한 시스템에서 사용된다.
2. 부동소수점(Floating-point) = 실수를 가수부 + 지수부로 표현한다.
가수 : 실수의 실제값 표현
지수 : 크기를 표현함. 가수의 어디쯤에 소수점이 있는지 나타냄
- 고정소수점에 비해 훨씬 더 큰 범위의 숫자를 표현할 수 있다. 이는 소수점의 위치가 고정되어 있지 않고, 부동한다는 개념에서 비롯된 것이다. 부동소수점 수는 일반적으로 정규화되어 있으며, 가수와 지수로 구성된다. 이 방식의 장점은 표현 가능한 숫자의 범위가 매우 넓다는 것이다. 그러나 구현이 복잡하고 연산 속도가 다소 느릴 수 있다는 단점이 있다. 따라서 부동소수점은 주로 과학 계산이나 그래픽 처리 등 큰 범위의 숫자를 다루어야 하는 경우에 사용된다.
ex) 123.45는 1.2345 x 10^2이다. 여기서 1.2345는 가수이고 2는 지수이다.
가수는 소수점 아래의 수를 나타내며, 지수는 10의 거듭제곱 수를 나타낸다.
컴퓨터에서는 이진법을 사용하기 때문에 가수와 지수 모두 이진수로 표현된다.
12.375는 이진 부동소수점으로 표현하면 1100.011이된다. 정규화하면 1.100011 x 2^3이다. 1.100011은 가수, 3은 지수이다.
부동소수점 연산에는 주의가 필요한데, 부동소수점의 특성상 반올림 오차나 정밀도 손실 문제가 발생할 수 있기 때문이다. 정확한 값을 필요로 하는 금융 계산 등에서는 적절하지 않을 수 있다.
패리티 비트 / 해밍 코드
모두 데이터 전송 오류를 감지하고 수정하는 데 사용되는 기술이다. 패리티 비트는 오류만 감지할 수 있지만 해밍코드는 오류를 감지하고 수정할 수 있다.
패리티 비트 - 간단한 오류 검출 방법으로, 보통 데이터의 비트 수가 짝수인지 홀수인지에 따라 결정된다.
홀수 패리티의 경우, 패리티 비트를 포함한 1 비트 수가 홀수가 되도록 설정한다.
짝수 패리티의 경우, 패리티 비트를 포함한 1 비트 수가 짝수가 되도록 설정한다.
ex) 짝수 패리티일 때 7비트 데이터가 1010001이라면, 1이 총 3개 이므로 짝수로 맞추기 위해 1을 더해야 한다.
답 : 11010001 (맨 앞이 패리티비트)
해밍 코드 : 데이터 전송 시, 1비트의 에러를 정정할 수 있는 자기 오류정정 코드
패리티비트를 보고, 1비트에 대한 오류를 정정할 곳을 찾아 수정할 수 있다.
ARM 프로세서
- Advanced RISC Machines. RISC(Reduced Instruction Set Computing) 구조를 기반으로 하는 마이크로프로세서이다.
1. RISC는 간단한 명령 집합을 사용하여 각 명령을 가능한 한 빠르게 실행하려고 한다. 프로세서는 더 적은 클럭 사이클로 더 많은 작업을 수행할 수 있다.
- 칩은 기본 설계 구조만 만들고, 실제 기능 추가와 최적화 부분은 개별 반도체 제조사의 영역으로 맡긴다. 따라서 물리적 설계는 같아도, 명령 집합이 모두 다르기 때문에 서로 다른 칩이 되기도 한다.
- RISC 설계 기반으로 '단순한 명령 집합을 가진 프로세서가 복잡한 것보다 효율적'임을 기반하기 때문에 명령 집합과 구조 자체가 단순하다. ARM 기반 프로세서가 더 작고, 효율적이며 상대적으로 느리다.
- ARM을 위해 개발된 프로세서는 오직 ARM 프로세서가 탑재된 기기에서만 실행할 수 있다.
하지만, 하나의 ARM 기기에 동작하는 OS는 다른 ARM 기반 기기에서도 잘 동작한다. 이러한 장점 덕분에 수많은 버전의 안드로이드가 탄생하고 있으며 또한 HP나 블랙베리의 태블릿에도 안드로이드가 탑재될 수 있는 가능성이 생기게 된 것이다.
Java
고유 락 : 동시성 제어를 위해 사용되는 중요한 도구 중 하나.
모니터 락이라고도 불리는 이 락은 자바의 모든 객체에 내장되어 있다.(모든 객체가 갖고 있으니 고유락이라고 한다.)
synchronized 블록이 이 고유락을 사용해서 락을 다룬다. -> synchronized 블록은 객체 단위로 락을 다룬다.
고유 락은 'synchronized'키워드를 사용하여 접근할 수 있다. 이 키워드는 메서드 또는 블록에 적용될 수 있으며, 해당 메서드 또는 블록이 실행되는 동안에는 해당 객체의 락을 취득하게 된다. 이 락은 메서드 또는 블록의 실행이 완료되면 자동으로 해제된다.
1. Intrinsic Lock (고유락)은 자바의 모든 객체가 가지고 있는 내장 뮤텍스이다. 객체의 내장 락에 접근하려면, 객체의 'syn'메서드를 호출하거나, 해당 객체를 대상으로 'syn' 블록을 사용해야 한다.
2. Reentrancy : 락이 재진입 가능하다는 개념을 나타낸다. 즉 이미 락을 취득한 스레드가 다시 같은 락을 취득할 수 있다는 것이다. 이는 스레드가 자신이 이미 소유한 락에 대해 블록되는 상황을 방지한다.
문자열 클래스
String
- new 연산을 통해 생성된 인스턴스의 메모리 공간은 변하지 않음 - 불변
- GC로 제거되어야 함
- 문자열 연산 시 새로 객체를 만드는 오버헤드 발생
- 객체가 불변하므로, 멀티스레드에서 동기화를 신경 쓸 필요가 없음. 조회 연산에 장점
- 문자열 연산이 적고, 조회가 많은 멀티스레드 환경에서 좋음
- String에 대한 모든 수정 연산(연결, 부분 문자열 추출 등)은 실제로는 새로운 String 객체를 생성한다.
- String 클래스는 내부적으로 문자 배열을 사용하여 문자열을 저장한다. 또한 String 클래스는 intern() 메서드를 통해 문자열을 재사용할 수 있는 기능을 제공한다. 이 메서드는 동일한 문자열에 대해 동일한 String객체를 반환하므로, 메모리를 절약할 수 있다.
StringBuilder
- 가변(mutable)하며, String과 달리 StringBuilder 객체는 수정될 수 있다.
- 내부적으로 문자 배열을 사용하여 문자열을 저장하지만, 이 배열은 필요에 따라 동적으로 확장될 수 있다.
- append(), insert(), delete() 등의 메서드를 통해 문자열을 효율적으로 수정할 수 있다.
- Thread-safe 하지 않다. 따라서 여러 스레드에서 동시에 StringBuilder 객체를 수정하면 문제가 발생할 수 있다.
StringBuffer
- StringBuilder와 매우 유사하지만, StringBuffer는 스레드 안전하다. 이는 StringBuffer의 모든 중요한 메서드가 synchronized 키워드를 사용하여 동기화되어 있다는 것을 의미한다. 따라서 여러 스레드에서 동시에 안전하게 사용될 수 있다. 하지만 이 동기화는 성능에 약간의 오버헤드를 추가하므로, 단일 스레드에서만 사용되는 경우 StringBuilder가 더 효율적일 수 있다.
Garbage Collection
- GC의 대상
- 객체가 NULL인 경우(ex. String str = null)
- 블럭 실행 종료 후, 블럭 안에서 생성된 객체
- 부모 객체가 NULL인 경우, 포함하는 자식 객체
- 메모리 해제 과정
- Marking
- 프로세스는 마킹을 호출한다. 이것은 GC가 메모리를 사용하는지 아닌지를 찾아낸다. 모든 객체는 마킹 단계에서 결정을 위해 스캔되어 진다. 모든 오브젝트를 스캔하기 때문에 매우 많은 시간을 소모하게 된다.
- 어떤 객체가 'reachable'하다고 표시한다. 'Reachable'하다는 것은 루트 객체(스레드, 스택 프레임, 정적 필드 등)에서 참조 체인을 통해 접근할 수 있다는 뜻이다. 즉 프로그램이 아직 해당 객체를 사용하고 있음을 의미한다.
- Sweeping(Normal Deletion)
- 'marked'되지 않은, 즉 'unreachable'한 객체들을 메모리에서 제거한다. 이렇게 해서 더 이상 사용되지 않는 메모리를 회수하여 재사용 가능한 상태로 만든다.
- 참조되지 않는 객체를 제거하고, 메모리를 반환한다. 메모리 Allocator는 반환되어 비어진 블록의 참조 위치를 저장해 두고 새로운 오브젝트가 선언되면 할당되도록 한다.
- Compacting : 일부 GC 알고리즘은 'compacting' 단계를 추가로 수행한다. 'sweeping' 단계 후에는 사용되지 않는 메모리가 여기저기 흩어져 있을 수 있다. 'compacting' 단계에서는 이런 메모리를 정리하여, 사용 가능한 메모리를 연속적으로 만든다.
- Marking
- Heap 메모리의 구조
- young, old 두가지 영역으로 설계하였다.
- young
- 새롭게 생성된 객체가 할당되는 영역
- 대부분의 객체가 금방 unreachable 상태가 되기 때문에, 많은 객체가 young 영역에 생성되었다가 사라진다.
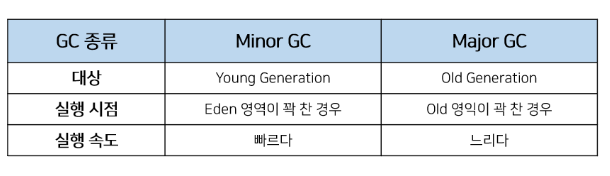
- Minor GC
- Eden, survival 0, survival 1로 나뉜다.
- Old 영역
- young 영역보다 크게 할당되며, 영역의 크기가 큰 만큼 가비지는 적게 발생한다.
- Major GC or Full GC
Primitive type & Reference type
기본형
- 모두 소문자로 시작된다
- 비객체 타입이므로 null 값을 가질 수 없다.(기본값이 정해져있음)
- 변수의 선언과 동시에 메모리 생성
- 모든 값 타입은 메모리의 스택에 저장됨
- 저장공간에 실제 자료 값을 가진다
참조형
- 기본형을 제외한 나머지
- 기본형과는 달리 실제 값이 저장되지 않고, 자료가 저장된 공간의 주소를 저장한다.
- 즉, 실제 값은 다른 곳에 있으며 값이 있는 주소를 가지고 있어서 나중에 그 주소를 참조해서 값을 가져온다
- 메모리의 힙에 실제 값을 저장하고, 그 참조값(주소값)을 갖는 변수는 스택에 저장한다.
- 참조형 변수는 null로 초기화 시킬 수 있다.







