7/1 ~ 7/7
7/1
리스트 불러올 때, 원본 그대로 불러오면 당연히 용량을 너무 많이 불러옴. 이미지 리사이징을 해야하는데,
나는 multipart를 사용 안하고, presigned url을 사용해서, 자바 코드로 서버에서 리사이징이 불가능함. (애초에 서버리스로 설계해서 서버를 통해 리사이징 한다는게 말이 안됨.) 그래서 aws lambda@edge를 사용해 원본 origin s3버킷에 접근해서 이미지를 받아올 때, cloud front에 캐싱이 되는데, 이 받아올 때 리사이징을 해서, cloud front에는 캐싱된 이미지를 저장하면 처음 요청시에만 좀 걸리고, 이후 요청부터는 캐싱 + 리사이징으로 인한 용량 저하로 매우 대단한 효과 나타남. !
그런데 계속 안되다가,
온갖 재시도 끝에 aws lambda@edge와 aws cloud9를 이용해 이미지 리사이징 성공.. node.js와 shark를 이용해 리사이징 코드를 lambda에 추가해서 기존 cloudfront와 연결하는 건데. 시행착오가 많았다. 아무래도 익숙하지 않은 node.js를 사용하려니 더 어려웠다.
1. 먼저 직접 폴더 만들고 vs code로 index.js추가하고 직접 압축해서 lambda에 올리려고 하니 실패.
2. cloud9 이용해서 진행하는데 aws lambda폴더에서 내가 만든 함수를 download 받으려 했는데, download 자체가 회색으로 막혀있다.(버튼은 있는데 안눌러짐). 이때 lambda 생성할 때, node.js 20으로 했어서 안나왔음. 아직 지원안되나?
3. 이후 node.js를 버전 18로 했더니 download나옴. 이후 과정은 블로그대로 진행했는데, cloudfront에 배포가 이상하게 매우 빨리 되고(원래 5분 걸린다고 나옴), 당연히 503에러나옴.

하.. 이거 지긋하게 만났네.
4. 마지막으로 node.js를 버전 16으로 낮추고 동일하게 재시도 하니 성공함. 왜??? 버전때문임?? 아직 왜 된지는 모르겠으나 매우 기쁨. 희열 느낌
코딩 여우 이미지 기존 184kb인데, 두 번째 요청부턴 ?h=50으로 한다고 하면, 2.5kb 리소스 자원 사용됨.즉, 리사이징을 통해 매우 빠르게 썸네일 이미지 가져올 수 있음.\
결국, 단건 프로필 조회와, 간병인 / 환자 찾기 목록 리스트 조회 모두 대폭적인 성능 향상을 이루어냄.
리스트 조회는 한 번 테스트 결과 2명의 간병인 존재하고 각각 이미지가 있다고 하면 리스트 조회가 첫 요청은 287ms에서 두 번째 요청 이후부터는 평균 30ms가 걸림.
즉, 이미지가 캐싱되었고, 리사이징된 이미지이기 때문에, 요청 시간 대폭 감소, size도 대폭 감소가 되었다.
https://velog.io/@su-mmer/CloudFront%EC%99%80-LambdaEdge%EB%A5%BC-%EC%9D%B4%EC%9A%A9%ED%95%9C-%EC%9D%B4%EB%AF%B8%EC%A7%80-%EB%A6%AC%EC%82%AC%EC%9D%B4%EC%A7%95
https://velog.io/@ygreenb/AWS-LambdaEdge-OnTheFly
========================
7/2
매칭 -> 계약으로 통합해서 개발 진행
- 계약 신청서 보낼 때,
- 본인의 기본 프로필 정보 - db
- 간병 기간, 시간, 금액(총 시간에 맞춰서, 야간인지 주간인지도 구분하고 추천 금액 제공) -별도 입력
- 이렇게 계약서를 만들어서 상대측에 전송한다. - 이를 위해선 먼저 프로필 등록 시에 간병서비스를 원하는 기간, 시간, 장소(실제 간병 진행될 장소) 등이 먼저 입력되어야 한다. (그래야 찾을 때 일정 맞는 사람한테 계약 신청을 보낼 수 있음) - 이렇게 진행하려 하는데 괜찮으신가요? 시간 같은 경우에는 구체적일수록 좋을 것 같습니다. (주간 2시간, 주간 8시간, 야간 2시간, 하루 종일 등
간병인은 프로필에 기간은 따로 없어도 된다. 매칭 리스트에 올리면 그거 자체가 이용 가능하단 것이므로 (?)
==========================
7/3
계약 시스템 재 구축, 리팩토링 진행함.
implementation 'org.xhtmlrenderer:flying-saucer-core:9.1.22'
implementation 'org.xhtmlrenderer:flying-saucer-pdf:9.1.22'
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'이용해서 html 받아서 pdf 추출 성공
===============================
7/5
계약 기능 완성했고
이제 검색 기능을 리팩토링 한다.
우선 리팩토링 전 jmeter로 테스트 돌려봄.
10 * 1 * 2 일 때,

50 * 1 * 2 일 때,


500 * 1 * 2 일 때,

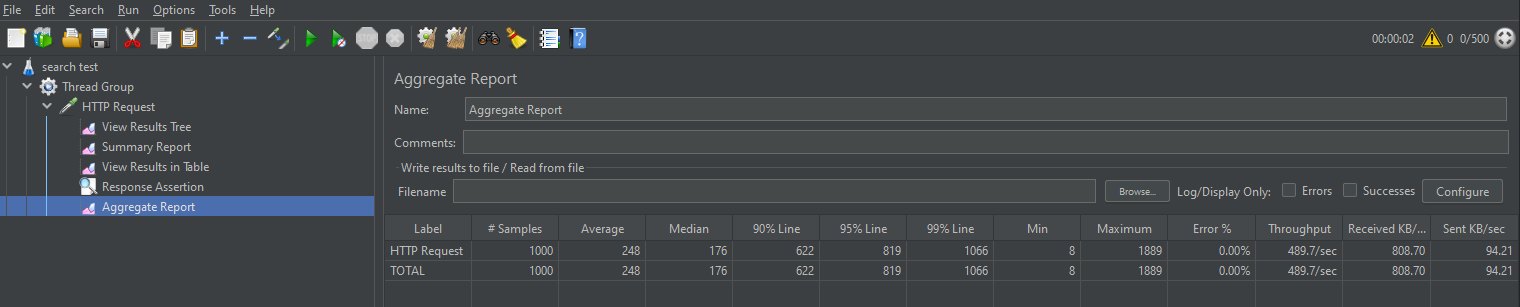
500 * 1 * 2 , page = 1,

page = 2
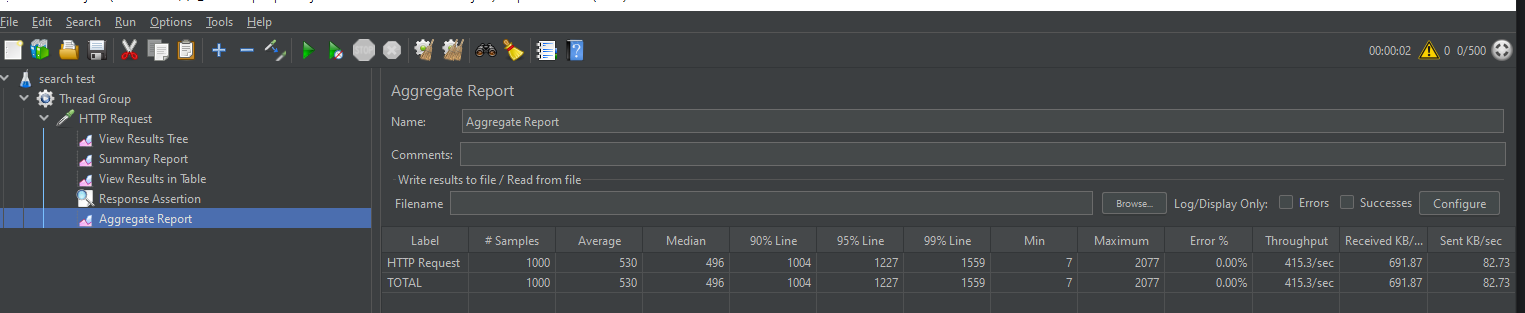
------------------------
search?firstAddress=경기도&sort=rating,desc


검색 기능 완벽하게 성능 올려보자.
elastic search? full text search? index? cache?
애초에 지금 문제는?
지금은 jpa로 검색 기능이다. 즉, rdb에서 like로 조회를 한다는 것임.
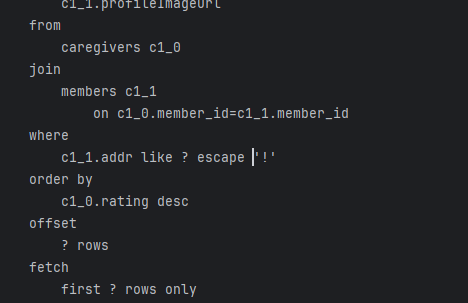
하지만 like는 기본적으로 full scan이기 때문에 시간이 오래 걸림.
그래서 역색인을 이용하는 elastic search를 써볼까? 더 빠르다는데.
아니, 간병인 리스트 찾기 시에, 간병인 특이사항이 매우 길수도 있다. 여기서 검색 시 full scan을 쓴다면 매우 오래걸릴 수 있다. 근데 나는 리스트 보여줄 때, 요약 정보만 보여주려고 했는데 (실제로 요약 정보만 화면에 보여주는 것이 맞다.) 그런데 디테일 정보(특이사항 등 포함)까지 search에 걸려야 한다. 어떻게 하는거지?
생각해보니 당연하다. 검색어(keyword) 입력 시, rdb에서 모든 row를 보면서 해당하는 keyword가 있는지 확인해서 그 결과를 가져오고, 거기서 dto로 화면에 보여주는 거네.
그럼 방금 말한대로, 환자 특이사항이나 간병인 특이사항이 매우 길어질 수 있고, 입력 정보가 많으므로
서로를 좀 더 자세하고 다양한 키워드로 검색이 가능하게 해야할텐데, jpa로만 검색을 구현 (=즉, rdb)하면 like로 인해 성능이 좋지 않다.
역색인이 되고 + 또한 유사어로도 검색이 가능한 elastic search를 도입하자. 그럴려면 검색 버튼이 있어야겠지?
elastic search + cache 로 성능 끌어올리자.
적어도 찾기와 계약 부분은 완벽하게 성능 끌어올리자.
하지만 학습 비용이 많고, 서비스 특성상 전체 검색의 효용이 그보다 높지 않기 때문에, 인덱스 설정으로 먼저 진행하기.
======================
7/6
querydsl 성능 개선
https://www.youtube.com/watch?v=zMAX7g6rO_Y&t=1199s
기존 쿼리 :
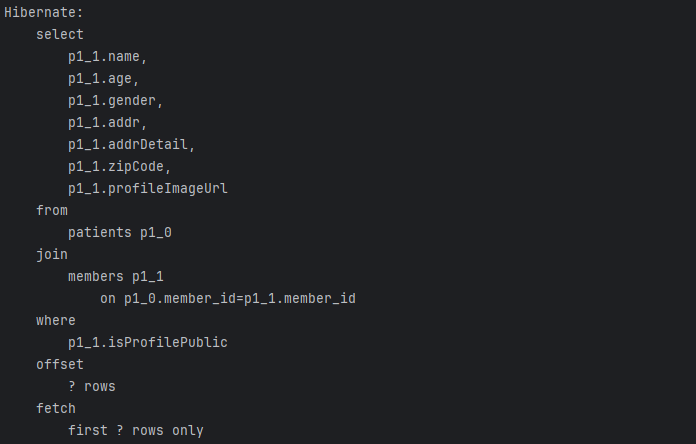
인덱스(커버링 인덱스) + JMeter + 쿼리 실행 계획 filtered 높게 이루어지도록 조회 쿼리 개선하자.
https://www.youtube.com/watch?v=zMAX7g6rO_Y&t=1199s
https://tjdtls690.github.io/studycontents/java/2023-11-05-covering_index/
https://jojoldu.tistory.com/476
https://jojoldu.tistory.com/243
https://jojoldu.tistory.com/528
https://tjdtls690.github.io/studycontents/java/2023-11-03-select_perform_improve/
==================================
7/7
caregiver 더미데이터 5,000,000 개 삽입 후, search api 호출 해봄 search?page=3

이렇게 부하 테스트 진행 시,


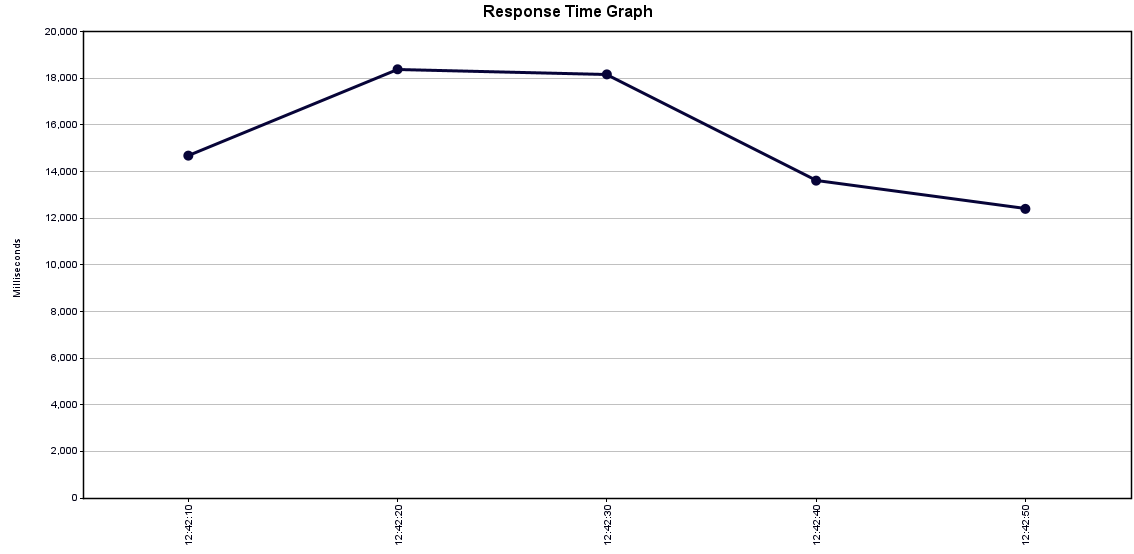
ERROR는 30초 넘어가서 500에러 난것임. 매번 존재함.
이때까지만 해도 코드를 잘못짰어서, count쿼리에서 그냥 다 가져 왔음.
select c1_1.name,c1_1.age,c1_1.gender,c1_1.addr,c1_1.addrDetail,c1_1.zipCode,c1_0.rating,c1_0.experienceYears,c1_0.specialization,c1_1.profileImageUrl from caregivers c1_0 join members c1_1 on c1_0.member_id=c1_1.member_id where c1_1.isProfilePublic limit 15,5;
select count(c1_0.member_id) from caregivers c1_0;
이렇게 가져온 결과가 위 결과임. 즉 제대로 된 코드가 아니였고 정확한 값이 아니란 것임.
그러나 속도는 그나마 빨랐다. 단건 조회 시 6초언저리, 부하 테스트는 위와 같았음. 원인은 count쿼리에서의 성능 향상이려나? 아니면 조건문이 없어서?

explain 실행 계획 이렇게 나옴. all.. 즉 full scan한다는 것임.
쿼리 : select c1_1.name,c1_1.age,c1_1.gender,c1_1.addr,c1_1.addrDetail,c1_1.zipCode,c1_0.rating,c1_0.experienceYears,c1_0.specialization,c1_1.profileImageUrl from caregivers c1_0 join members c1_1 on c1_0.member_id=c1_1.member_id where c1_1.isProfilePublic limit 15,5;
select count(c1_0.member_id) from caregivers c1_0;
=====================위는 코드 수정전 모든 페이지 다 조회할때, 즉 카운트 쿼리에 조건 없을 때임====================================
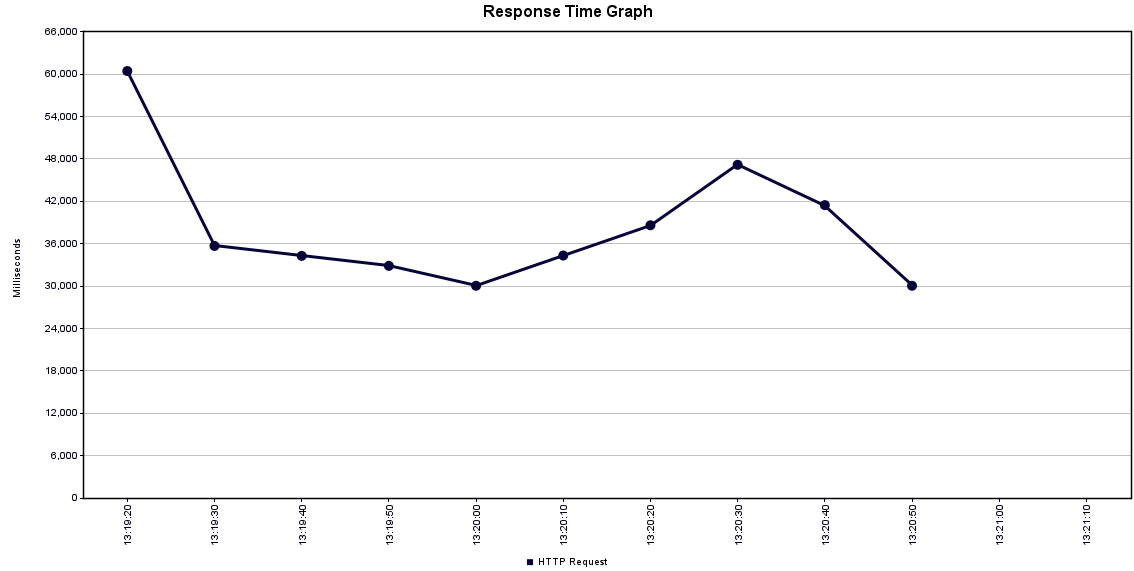
여기서 부터는 카운트 쿼리 로직 수정 후 임.
단건 조회 시,

기본 38초 이상이 걸리네. 즉 매우 느리다. 조건과 정렬을 넣은 것보다 느리다. 왜???????

쿼리 :
select c1_1.name,c1_1.age,c1_1.gender,c1_1.addr,c1_1.addrDetail,c1_1.zipCode,c1_0.rating,c1_0.experienceYears,c1_0.specialization,c1_1.profileImageUrl from caregivers c1_0 join members c1_1 on c1_0.member_id=c1_1.member_id where c1_1.isProfilePublic limit 15,5;
select count(c1_0.member_id) from caregivers c1_0 join members c1_1 on c1_0.member_id=c1_1.member_id where c1_1.isProfilePublic;
즉, 500만건에서는 그냥 다 에러가 나온다.
근데 신기한게 page=3쿼리가 조건 이것저것 넣은것보다 더 성능이 느린거같은데?
위에가 page=3쿼리인데 에러율이 밑에 조건 넣은것보다 더 높다.
왜지?
============================================
postman으로 단건 조회 시,
http://localhost:8080/api/v1/patient/search?page=5000&firstAddress=수원시 영통구&sort=rating,desc

http://localhost:8080/api/v1/patient/search?page=50&firstAddress=수원시 영통구&sort=rating,desc


평균 25초 이상이 걸린다.
jmeter로 부하 테스트 시에는,
api/v1/patient/search?page=50&firstAddress=수원시 영통구&sort=rating,desc


그냥 서비스 불가능할 정도이다.
쿼리 :
EXPLAIN select c1_1.name,c1_1.age,c1_1.gender,c1_1.addr,c1_1.addrDetail,c1_1.zipCode,c1_0.rating,c1_0.experienceYears,c1_0.specialization,c1_1.profileImageUrl from caregivers c1_0 join members c1_1 on c1_0.member_id=c1_1.member_id where c1_1.addr like '%수원시 영통구%' escape '!' and c1_1.isProfilePublic order by c1_0.rating desc limit 250,5;
EXPLAIN select count(c1_0.member_id) from caregivers c1_0 join members c1_1 on c1_0.member_id=c1_1.member_id where c1_1.addr like '%수원시 영통구%' escape '!' and c1_1.isProfilePublic;
select c1_1.name,c1_1.age,c1_1.gender,c1_1.addr,c1_1.addrDetail,c1_1.zipCode,c1_0.rating,c1_0.experienceYears,c1_0.specialization,c1_1.profileImageUrl from caregivers c1_0 join members c1_1 on c1_0.member_id=c1_1.member_id where c1_1.addr like '%수원시 영통구%' escape '!' and c1_1.isProfilePublic order by c1_0.rating desc limit 250,5;
select count(c1_0.member_id) from caregivers c1_0 join members c1_1 on c1_0.member_id=c1_1.member_id where c1_1.addr like '%수원시 영통구%' escape '!' and c1_1.isProfilePublic;
이 쿼리가 근데 그냥 ?page=3 호출했을 때 쿼리보다 속도가 빠름. 왤까?
-------------------------------
본격적인 조회 성능 개선
1. full text index 도입
ALTER TABLE members ADD FULLTEXT INDEX ft_idx_addr (addr);
addr 컬럼에 ft idx 적용함.
하지만 문제 상황. jpa는 full text index를 지원하지 않음. 그래서 직접 native sql을 짜야함.
예를 들어
@Query(value = "SELECT * FROM menu_review WHERE MATCH (comments) AGAINST (?1 IN BOOLEAN MODE )", nativeQuery = true)
List<MenuReview> searchFullTextComments(String keyword);이렇게.
하지만 나는 이런식으로 할 수 없는 것이, querydsl로 동적 쿼리가 진행중이다. 즉, 일반적인 리포지토리(PatientRepository)에서 조회하는 것이 아니기 때문에 @Query를 사용하는 것이 불가능하다.
그래서 querydsl 코드 내에서 해결을 해야하는데,
찾아본 방법이 1. mysqlDiaract를 상속받은 커스텀방언을 만들어서 함수를 match 진행 후 적용.
ex.
public class CustomDialect extends MySQL56SpatialDialect {
private MySQLSpatialDialect dialectDelegate = new MySQLSpatialDialect();
public CustomDialect() {
super();
this.registerFunction("distance",new StandardSQLFunction("ST_Distance", StandardBasicTypes.DOUBLE));
this.registerFunction("match", new SQLFunctionTemplate(StandardBasicTypes.DOUBLE, "match(?1) against (?2 in boolean mode)"));
}하지만 이 방법은 hibernate 6 부터 registerFunction 메서드가 없어져서 애초에 컴파일 자체가 불가능했다.
그래서 최신순으로 검색 돌리니까 hibernate 6부터 사용 가능한 방법을 알려준 블로그가 있다(=천사)
https://blogshine.tistory.com/692
위 블로그 보고 진행하니 따로 커스텀 만들지 않아도 match against 함수가 적용 되었다.
그래서 우선 1번 성능 개선 full text index 적용 결과는
먼저 match against in boolean mode와
match against IN NATURAL LANGUAGE MODE
쿼리 :
select c1_1.name,c1_1.age,c1_1.gender,c1_1.addr,c1_1.addrDetail,c1_1.zipCode,c1_0.rating,c1_0.experienceYears,c1_0.specialization,c1_1.profileImageUrl from caregivers c1_0 join members c1_1 on c1_0.member_id=c1_1.member_id where match(c1_1.addr) against ('수원시 영통구' IN NATURAL LANGUAGE MODE)>0.0 and c1_1.isProfilePublic order by c1_0.rating desc limit 250,5;
select count(c1_0.member_id) from caregivers c1_0 join members c1_1 on c1_0.member_id=c1_1.member_id where match(c1_1.addr) against ('수원시 영통구' IN NATURAL LANGUAGE MODE)>0.0 and c1_1.isProfilePublic;
단건 조회 시,

의문 1. 복잡한 조건 페이징이 일반 요청보다 더 빠른 이유는?
=================
더 적용해볼만한 거 : 우선 지역 검색이 주로 이루어질 것 같다. ex) '경기도 수원시 영통구'
현재는 addr 컬럼에 모두 넣고 있다 addrDetail은 세부주소임 (청명로 19번길 ~~)
즉, 테이블 검색 시 매번 full scan임. 인덱스 적용한다해도 결국 탐색하는 시간 필요함
그래서 자주 검색하는 주소(경기도 수원시 영통구)마다 검색하면 캐싱기능으로 저장해두고 이후 추가 검색하면 바로 반환하면 어떨까.