6/24 ~ 6/30
6/24
1. jmeter로 속도 측정 하려다가,
프로필 컨트롤러 수정, 삭제, 조회 메서드에서 @Pathvariable을 안쓰고 있었다는 사실을 발견..!
안쓰고도 할 수 있지만 rest api 형식은 넣어줘야 한다. 왜? => 더 자세히 찾아보기
그래서 @Pathvariable 를 넣고 서비스에서 getMember, getPatient로 두 번 리포지토리에서 데이터를 가져오던걸 findByIdAndMemberUsername을 통해 한번에 환자 프로필을 가져오게 됨. 멤버와 환자가 동일한지도 자동 검사 가능.
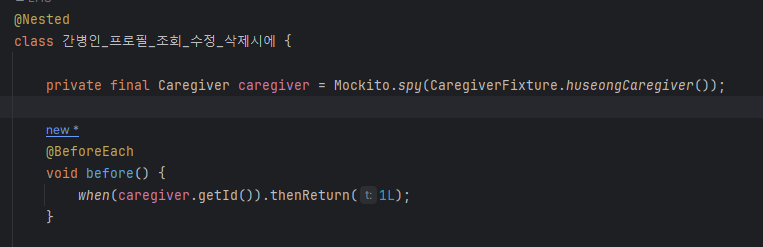
이렇게 리팩토링을 하고 테스트를 수정하려는데, 바뀐 메서드들 매개변수에 기존 매개변수에 Long id가 추가됨.(Pathvariable Long id의 id) 그런데 단위 테스트는 @Autowired가 없다. 즉, jpa 영속성 컨텍스트가 관리해주는 id가 없다. 영속성컨텍스트에서 flush를 통해 save를 해야 id가 생성이 되는데, 단위테스트에서는 영속성 컨텍스트가 없다. 그래서 id가 null로 들어오고, 테스트가 계속 실패함. => 방법 찾아보니 Mockito.spy()가 존재함. id를 임의로 넣어줄 수 있음. 어떤 원리임?? spy란? 더 찾아보기..
==============
프로필 컨트롤러 조회 테스트시,

각각 돌리면 성공하는데,
동시에 이 클래스 돌리면 아래먼저 실행되고 위 실행되는데 위 테스트 실패함. 왜??????? 독립성이 부족한가
3. 왜 Member 엔티티를 getMember로 리포지토리에서 조회시에, 환자와 간병인 엔티티를 조회하는 쿼리가 다 날라가지? LAZY로 했는데 왜 그러지?


???? 여기서 getMember~를 할 때, Member 한 번, 간병인 한 번, 환자 한 번 총 3번 쿼리가 나간다.
patient 1번 -> 3번 -> update.
그니까 member를 가져올때 3번 쿼리가 나가는건데, 왜?? Member클래스는 프록시라고 나와서 초기화도 안된 상태인데 왜 세 번 호출될까?
연관관계 설정에 문제가 있나?
해결 => 아직
chat gpt : 양방향 연관관계에서 연관관계의 주인이 아닌 엔티티(Post)를 조회할 때 FetchType.LAZY가 작동하지 않는 이유는 다음과 같습니다:
- 프록시 생성 문제: JPA는 지연 로딩을 위해 프록시 객체를 생성해야 합니다. 그러나 연관관계의 주인이 아닌 엔티티를 조회할 때, JPA는 연관된 엔티티가 존재하는지 여부를 알 수 없습니다. 이는 데이터베이스 레벨에서 해당 엔티티의 존재 여부를 판단할 수 있는 정보가 없기 때문입니다.
- NULL 및 프록시 할당: JPA는 연관관계의 주인 엔티티를 조회할 때, 외래 키(FK) 컬럼을 통해 연관된 엔티티의 존재 여부를 확인할 수 있습니다. 그러나 연관관계의 주인이 아닌 엔티티는 이러한 정보가 없기 때문에 프록시를 생성할 수 없고, 결국 즉시 로딩(EAGER)으로 처리하게 됩니다. === 즉, 연관관계의 주인인 Patient는 Member_id를 fk로 가지고 있어서, 있으면 프록시 생성, 없으면 null 처리가 가능한데, 반대로 member는 patient정보를 가지고 있지 않기 때문에 eager로 작동하게 된다.
단방향 연관관계에서는 문제가 없나?
단방향 연관관계에서는 이 문제가 발생하지 않습니다. 이는 단방향 연관관계에서 연관된 엔티티의 존재 여부를 쉽게 판단할 수 있기 때문입니다.
https://1-7171771.tistory.com/143
해결 방법
해결 방법이라고 했지만 완벽하게 이 문제를 해결할 수 있는 방법은 존재하지 않는다. 따라서 아래와 같은 해결책을 고려한 후 현재 상황에 알맞게 적용해야 한다.
- 구조 변경하기
- 양방향 매핑이 반드시 필요한 상황인지 다시한번 생각해본다.
- OneToOne -> OneToMany 또는 ManyToOne 관계로 변경이 가능한지 생각해본다.
- 구조를 유지한채 해결하기
- CART를 조회할때 USER도 함께 조회한다. (Fetch Join)
- batch fetch size를 사용한다.
쿼리를 각각 두번 해서 결과값 각각 가져와서 예외 처리 세밀하게. 하는 것과
vs
한번에 조인쿼리로 한방에 값 가져오는 방법


vs

인데, 위에는 patient 한번 member한번이라 치고(아직 아님) 세밀한 예외 처리 가능
밑에는 조인쿼리로 한방에 불러오지만 caregiver의 member가 username의 본인인지 확인 할 수 있나? username 을 조작해서 jwt는 내걸로 인증했지만 caregiverId를 다른걸 넣어서 postman으로 호출하면? 에러는 나겠지만 간병인 존재 안함 이라는 에러 메세지가 나옴. 권한이 없어 수정할 수 없습니다.라는 에러가 나와야하는데말이지. 위 코드는 세밀한 예외 처리 가능.
====================
6/26
위처럼 fetch join을 하려 했는데, 근데 모든 쿼리에 fetch join을 해야 하는 문제가 발생함..
원인이 member, patient, caregiver가 각각 다른 엔티티라 그런 것임. member에 patient, caregiver 필드가 있으니 조회 쿼리가 다 나가는 것. 해결하려면 애초에 설계를 상속으로, join 전략으로 하면 됨.
JPA 상속 매핑 전략을 단일 테이블 -> join 전략으로 수정함. 이유 : 시스템 통합에 좋고, JOIN에 의한 성능 저하는 어느정도 제어 가능. 싱글테이블로 하면, 아마 환자나 간병인 세부 입력 필드가 굉장히 많아질텐데, 단일 테이블 크기가 너무 커져서 오히려 성능 나빠질 위험 존재. => JOIN 전략 채택.
하지만 JOIN 전략을 사용하니. Member로 먼저 가입하고 Caregiver를 프로필 등록 시에 엔티티 저장하는 방식이 안됨. 왜냐하면 caregiver 생성 시 member를 넣자니, caregiver 필드 내에 member가 있어야 하고, member에서 username, password 등을 가져와 생성하자니, caregiver가 생성될 때, Member도 같이 생성되어 저장(caregiver에 member_id만 보유)되므로, 사실상 다른 member2가 생성되고 username이 유니크 제약조건에 걸린다. 즉 다른 member가 생성되는 것이다.
JOIN 전략 단점 : INSERT, UPDATE 쿼리가 두 번 나감. caregiver 등록 할때, caregiver엔티티에 한 번, member에 한번.
조회를 join을 이용하여 한번에 조회함.
근데 member 하위 클래스인 patient, caregiver에서 생성자 Builder가 안되네?!
=> @SuperBuilder로 해결?
======================================
6/27
1. 7월 둘째주 까지 모든 기능 구현 끝내기.
2. 현재 수동 배포 진행중. jenkins or actions로 ci/cd 진행해야함.
3. 도커 사용해서 배포 ci/cd 진행해봐야함. (팀원들에게 설명도 해야함 - 자세히 학습)
4. erd 구조 수정해야함
5. 알림 기능에서 위에 나와있는 주석 부분 시도하기.
===================================
6/28
jmeter를 처음으로 시도해봤다. 실제 api가 호출되는거라, 반복 호출이 가능한 api를 주로 테스트하면 되겠다.(주로 조회 겠지?) 뭔가 성능이 안나올것 같거나 병목이 일어날거같은 api를 미리 시간을 재놓고, 리팩토링 or 기술 도입 후 다시 성능 측정해서 기록하자.
현재 도커를 이용해서 배포는 성공했다. 근데 ci/cd 진행하려고 보니 github actions가 아예 작동하지 않네?? 왜??
===================================
6/29
1. 이력서 글 작성함. aws s3, presigned url에 대한 글.
근데 작성하다보니 매개변수로 imageName 넘기는 것보다, ThreadLocal을 사용하는게 낫다는 생각이 듦.
리팩토링 하자. 그리고 aws lambda같은 서버리스 서버 사용해서도 추가하자. 전처리, 리사이징, 성능 개선을 목표로 리팩토링 하자.
aws lambda 참고 :
이미지 리사이징 중, aws lamda 함수 적용 시에,
- Unzipped size must be smaller than 262144000 bytes
이렇게 뜨네. zip 파일용량 242mb인데.. 262까지 가능하단 건데 왜 안되지?\
gpt는 zip 파일이 50mb 넘으면 안된다네. 난 왜이리 높지?
zip 파일 용량 줄이는 방법은?
=====================
6/30
갑자기 계속 build 시에
Error: Could not find or load main class com.patientpal.backend.BackendApplication
Caused by: java.lang.ClassNotFoundException: com.patientpal.backend.BackendApplication
가 나옴.. 다른 프로젝트 들은 다 정상동작하는데 patientpal만 에러남.
main 브랜치에서도 에러남. 그래서 설정 문제 인줄 알았는데,
우선 인터넷 서칭에서 나오는 방법 대부분이 해결이 안됐다.
그래서 인텔리제이 완전히 닫고, 프로젝트 폴더에서 .idea를 지웠다가 다시 실행하였고,
그리고 분명 feat/refactor-image 브랜치에서 작업을 하고 있었는 줄 알았는데, github desktop으로 들어가니 main 브랜치에 작업 내용이 남아있고, 진행중이였다. image 브랜치에서는 아무것도 없고. 이런 게 자꾸 일어나는 것 같은데, 왜 그럴까? 왜 분명 브랜치 만들어서 작업을 했는데, 실제 깃허브 데스크탑으로 들어가면 main브랜치에 작업이 발생하고 있는건 뭐때문일까?
그리고 다시 본론으로 돌아와서 gradle-wrapper.jar하고 gradle-wrapper.properties가 커밋 내역에 존재했다. 파일 내부는 똑같지만 변경사항이 있다고 하며 커밋 내역에 올라왔고, 알림 같은게 나왔다. 기억은 잘 안남. 알림으로 뭔가 나왔고, 그 변경사항들을 깃 데스크탑에서 작업내용 버림으로써, 커밋 내역에 안나왔고, 이제 잘 실행되었다.
아마 main 브랜치에서도 똑같은 에러 나왔던건, 아마 방금 언급한 image 브랜치에서 작업했다고 생각했던 내용이 main에서 발생한거라 (즉, 두 브랜치 모두에게 영향을 미친거라) 다 빌드 에러가 나지 않았을까. 그리고 어제밤 aws lambda를 진행하며 gradlew buildZip 같은 걸 건드리며 기존 gradle 관련 파일들에 영향이 가지 않았나 싶다.
aws cloud front 도입하여 cdn 캐시 기능 도입. (cdn이란?? 더 자세하게 공부)






----------------------
2 try

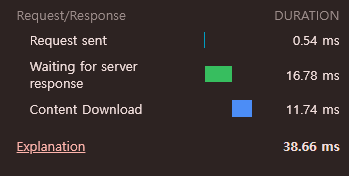
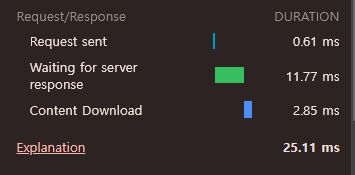
캐시 히트라면 평균 30 ~ 60 ms 가 걸린다.
다음 성능 개선 : 아마 제일 많이 사용하는 서비스가 간병인 찾기 / 환자 찾기 일 것이다. 즉, 검색이라는 것이다. 여기서 성능 향상 방법을 찾자. 아마 캐싱(레디스), 인덱스, 풀테이블스캔 등이 있을 것이다.
근데 성능 테스트를 하려면 충분한 데이터가 있어야 한다. 데이터를 직접 넣든가(반복으로 중복 제거하고) 공공데이터(있나?)찾아서 넣자.
이후 모니터링 prometeus, grafana 등 모니터링 방법도 찾자. 로깅 관리도 어떻게 하는지 해보고.
-------
생각해보니 리팩토링을 했어도, 프로필 삭제기능은 있어야함. 환자를 바꿔서 이용하고 싶을 수 도 있으니. 그래서 수정할 때는 이름, 주민번호, 폰번호 같은건 못바꾸고 주소, 특이사항, 사진 등만 수정 가능함. -> 따로 브랜치 파서 진행.