MySQL - Full Text Search는 전문 검색용이 아니다.
프로젝트를 진행하며 검색 기능을 할 때가 되었습니다.
매칭 신청을 보내기 위해서는 먼저 상대측 리스트를 검색할 필요가 있습니다.
다양한 방법이 있었고, 먼저 MySQL의 Full Text Search를 적용해보기로 하였습니다.
사용자의 원활한 검색을 위해 Querydsl을 이용해 동적 검색을 할 수 있게 하고 정렬 또한 최신순, 조회순, 후기순으로 가능하도록 진행하였습니다.
1. 첫 번째 문제 발생 : Full Text Search를 하기 위해서는 Match (1)... against (2)...라는 문법을 사용하여야 합니다. (2)-검색어에 해당하는 (1)-컬럼 을 조회하는 것입니다. 하지만 JPA은 full text search 문법을 지원하지 않습니다. 만약 사용한다면 직접 NativeQuery를 날리는 방법이 있습니다. Querydsl 역시 지원되지 않습니다. 하지만 만약 검색에 일반적인 JPQL을 사용했다면 직접 네이티브 쿼리를 짜면 해결이 되는 문제였지만, 동적 검색을 위한 Querydsl 코드에서 Match against 문법을 적용하는 것은 다른 문제였습니다.
이를 해결하기 위해 검색을 진행하였고 가장 많이 나온 방법은 dialect 를 custom하게 새로 만들어 custom dialect 를 어플리케이션 설정 정보에 등록하는 것입니다.
public class CustomDialect extends MySQL56SpatialDialect {
private MySQLSpatialDialect dialectDelegate = new MySQLSpatialDialect();
public CustomDialect() {
super();
this.registerFunction("distance",new StandardSQLFunction("ST_Distance", StandardBasicTypes.DOUBLE));
this.registerFunction("match", new SQLFunctionTemplate(StandardBasicTypes.DOUBLE, "match(?1) against (?2 in boolean mode)"));
}이런 식으로 직접 함수를 등록하는 방식입니다. 하지만 registerFunction()은 hibernate 5까지만 지원하였습니다.
현재 제가 적용하고 있는 Hibernate 6 버전부터는 deprecated되었죠.
6버전 부터는 방식이 약간 다릅니다.
public class CustomMariaDbFunctionContributor implements FunctionContributor {
@Override
public void contributeFunctions(FunctionContributions functionContributions) {
BasicType<Double> resultType = functionContributions
.getTypeConfiguration()
.getBasicTypeRegistry()
.resolve(StandardBasicTypes.DOUBLE);
functionContributions.getFunctionRegistry()
.registerPattern("match", "match(?1, ?2) against (?3 WITH QUERY EXPANSION)", resultType);
}
}이렇게 FunctionContributor를 implements하고
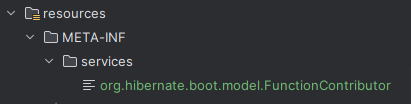
이 경로에 파일을 추가해줍니다.
그리고
com.patientpal.backend.config.CustomMariaDbFunctionContributor이 내용을 넣어줍니다. hibernate 5까지 진행했던 custom 설정 정보를 applcation.yml에 넣어주는 대신 이 경로에 넣어주는 거라고 생각하면 될 것 같습니다.
public BooleanExpression keywordSearch(String word) {
if (word == null || word.isEmpty()) {
return null;
}
return Expressions.numberTemplate(Double.class,
"function('match',{0},{1},{2})", caregiver.address.addr, caregiver.name, word).gt(0);이후에는 이런 식으로 querydsl에서 사용하면 실제 쿼리가 호출될 때, 알맞게 매개변수에 값이 들어가게 됩니다.
참고 :
https://aregall.tech/hibernate-6-custom-functions#heading-the-hibernate-meta-hint-file
https://blogshine.tistory.com/692
이렇게 저는 Full Text Search를 하기 위한 모든 준비를 마쳤고, 실제로 테스트를 진행해 보았습니다.
But,,
2. 두 번째 문제 : full text index 적용 후 대용량 데이터 검색 시, 응답 속도 매우 느림
저는 현재 테스트 데이터 500만개를 넣어서 검색 시 조회 요청을 하고 있습니다. (추후 서비스 이용자 수 증가 고려)
하지만 keyword가 포함된 데이터가 많을 수록 성능은 매우 느려졌습니다.
즉, 현재 데이터 대부분의 지역은 서울시 000구로 설정이 되어 있습니다. (대부분의 거주자 서울 거주 고려)
이러한 상황에서 검색어에 서울시 or 서울시 00구 로 검색을 진행할 시에 결과가 아예 반환되지 않습니다.


언젠가 될까 싶어 계속 기다려봤지만 6분이 지나자 에러가 발생하였습니다.

FTS query exceeds result cache limit 에러는 MySQL의 FULLTEXT 검색 결과에서 너무 많은 결과가 반환되어 캐시 한도를 초과하였다는 에러입니다. 즉, MySQL이 감당할 수 없을 만큼의 결과를 반환했다는 것이죠.
위 테스트 결과로 미루어봤을 때, Full Text Search는 대용량의 데이터 검색에서는 상당한 비효율(어쩌면 매우)이라는 점입니다.
저와 같은 경험을 한 사람들을 찾아보았습니다.
https://data-sleek.com/the-limits-of-mysql-full-text-search-and-the-quest-for-alternative-solutions/
https://www.clien.net/service/board/cm_app/17393973
이 글을 요약하자면 쿼리가 복잡함에 따라, 또한 데이터가 증가함에 따라 성능이 매우 느려진다는 것입니다.
원인은 Inno_DB를 사용하는 MySQL의 Full Text Search 자체의 버그라고 합니다. (https://medium.com/hackernoon/dont-waste-your-time-with-mysql-full-text-search-61f644a54dfa)
MySQL이 인덱스를 병합하는데 능숙하지 않기 때문이라고 합니다. 즉, 간단한 쿼리에서는 FTS가 잘 작동하지만, 조건절이 추가로 붙는다면 1. 해당하는 단어에 대한 전체 스캔 2. 스캔한 결과와 추가 조건들간에 Cross Join 수행 후 결과 반환이러한 과정을 거치기 때문에 시간이 매우 느려지고, 사용할 수 없게 됩니다. 이는 스캔한 결과가 많을 수록 더욱 느려짐이 자명하겠죠.
다른 분 경험 :

현재 프로젝트 대용량 데이터 테스트 시에 Full Text Search 사용이 불가능했던 가장 결정적인 이유는 검색 시에 Default값으로 최신순 정렬을 해야 했기에, 항상 모든 쿼리에 order by member_id가 실행된다는 것입니다. 또한 매칭 리스트에 올리고 싶은 유저들만 조회 해야 했기에 where 절에 isProfilePublic = 1 도 항상 조회에 포함이 되었습니다. 물론 이를 막기 위해 isProfilePublic이 true인 테이블을 정규화를 통해 분리할 수 도 있겠지만, 리스트에 등록/삭제 시 매번 테이블간에 동기화를 해준다는 것 자체가 상당한 비용이 들거라 생각하였습니다.
이러한 이유로, 직접 해본 테스트 시에도 도저히 실제로 사용할 수 없을 만큼의 시간이 걸렸고, (6분 지나자 에러 발생) 이는 FULLTEXT INDEX의 설정 문제가 아닌, MySQL의 Full Text Search의 한계였습니다.
물론 데이터가 많지 않고, 검색에 다른 조건이 붙지 않는다면 FTS는 훌륭한 선택이 될 수 있습니다. 하지만 항상 변화에 유연하게 대응해야한다는 개발자스러운 생각이 있기 때문에 추후 서비스 확장 가능성 또는 검색 조건 추가, 정렬 추가 등 요구사항 변화가 생겼을 때, FTS로 모든 것을 해결했다면, 추후에 저희는 더 고통받을 수 있습니다. 대량의 데이터, 복잡한 검색 조건, 다양한 요구사항 추가 가능한 상황이라면 애초부터 전문 검색 엔진인 ElasticSearch, Apache Solr, Amazon CloudSearch 등을 고려하는 것이 좋을 것 같다고 생각합니다.